At the end of every semester, and especially the last two when I’ve taught CS1, I always have the same thoughts about grade inflation and the meaning of grades. This is a particular problem for CS1 because somewhere between a third and a half of the students get A-‘s or A’s – a much larger proportion than in other introductory courses. One possible interpretation is that I grade too easily, but other interpretations are possible. Two in particular come to mind:
- The course structure allows students to get objectively higher grades. I’ve written about the lack of exams and the frequent, low-stakes grading structure. I also allow unlimited autograder submissions, which means that students can tweak their code until they pass all the test cases. The autograder also provides immediate feedback, which leads to…
- Students spend more time on this class. The data from the end-of-semester teaching evaluations support this: over both semesters (59 respondents total), the median and average time spent on this course outside of the classroom is 6 and 8.4 respectively. Keep in mind that this course already has 6 hours of lectures and labs per week, and that a course is supposed to take about 10 hours total.

(This plot omits one student who reported spending over 40 hours per week on this course. I really hope they were exaggerating.)
The real answer to the high grades is likely some combination of all three explanations. What I can’t decide is what this means in terms of the grading structure of the course. I am less concerned about grade inflation than I am about the distribution of grades. I wrote in the previous post that my “quizzes” are tri- or quad-modal. It turns out that my final grades are not as bad, but are still bi-modal, with peaks around 85% and 95%.
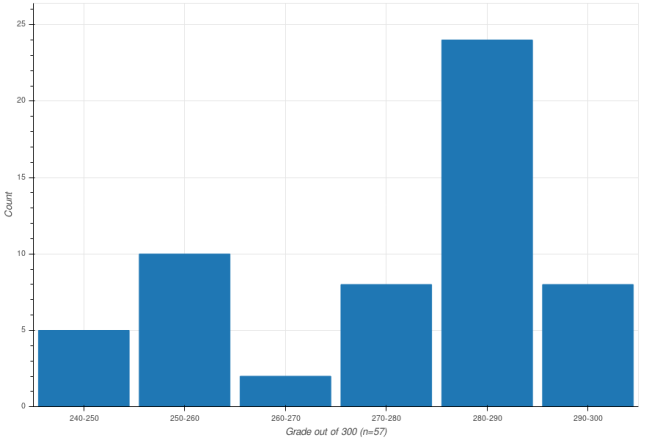
(Grades lower than B- have been omitted.)
As with grade inflation, there is the question of what this means, and there is the meta-question of whether it is problematic. The face-value explanation would that there are two groups students – one that gets computer science, and one that doesn’t. I’m undecided whether this describes the “true” distribution of computer science competency, but philosophically as a teacher I should not design courses with this assumption. If instead I take for granted that student skill levels are unimodal, then what the grade distribution would suggest is that I am not sufficiently sensitive to students some middle section of that curve.
One thing I do know is that this is not a problem I can fix by changing the grading structure but keeping the same assignments. I know this because I have iterated through the space of assignment weights. Within the constraints of low-stake assignments, no set of weights would transform the existing grades of my students into a unimodal distribution peaking around B or B+. What this means to me is that if I am indeed failing to identify the B+ students, the place to start would be to look at the actual content of the assignments.
I don’t have a takeaway from this. I dislike the bimodal distribution of grades, but it’s unclear whether I am justified in my dislike, and even if so, what I can do to change it. Assigning grades, as well as deciding on the grading structure of a course, requires thinking through not just what students should learn and whether their grade reflects that, but also how we trade off student achievement, time spent, and the value of negating institutional grade inflation. As a final thought, it has occurred to me that perhaps grades are not the venue to demonstrate these nuances. Perhaps grades should be seen only as the carrot-and-stick, with more emphasis put on detailed feedback provided through other channels.
